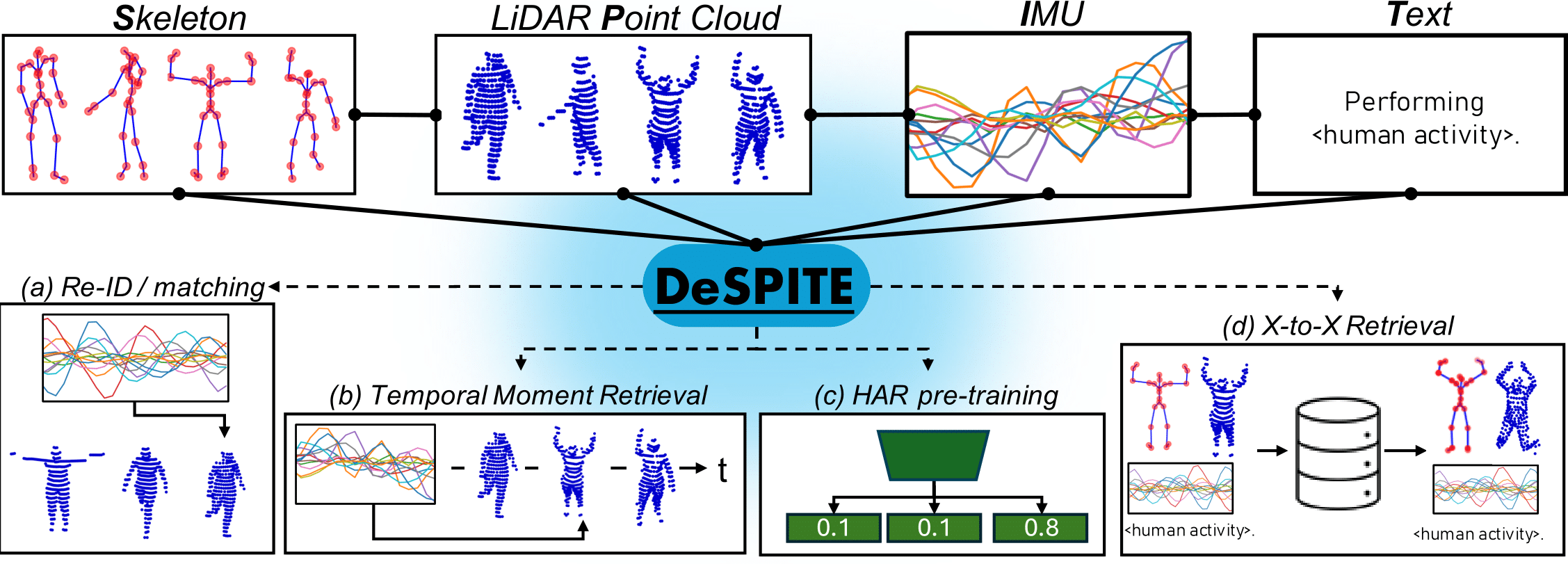
Despite LiDAR (Light Detection and Ranging) being an effective privacy-preserving alternative to RGB cameras to perceive human activities, it remains largely underexplored in the context of multi-modal contrastive pre-training for human activity understanding (e.g., human activity recognition (HAR), retrieval, or person re-identification (RE-ID)). To close this gap, our work explores learning the correspondence between LiDAR point clouds, human skeleton poses, IMU data, and text in a joint embedding space. More specifically, we present DeSPITE, a Deep Skeleton-Pointcloud-IMU-Text Embedding model, which effectively learns a joint embedding space across these four modalities. At the heart of our empirical exploration, we have combined the existing LIPD and Babel datasets, which enabled us to synchronize data of all four modalities, allowing us to explore the learning of a new joint embedding space. Our experiments demonstrate novel human activity understanding tasks for point cloud sequences enabled through DeSPITE, including Skeleton<->Pointcloud<->IMU matching, retrieval, and temporal moment retrieval. Furthermore, we show that DeSPITE is an effective pre-training strategy for point cloud HAR through experiments in MSR-Action3D and HMPEAR.
Given an IMU sequence, we can compute the similarity to point cloud sequences. In this demo, we visualize the embedding cosine similarity (bottom right) in every frame of the IMU query embedding (bottom left) of one subject to the point cloud sequence embeddings of all subjects. Each subject is color coded by their similarity in each frame.
In addition to matching/RE-ID, the embeddings also generalize directly to temporal moment retrieval/search in a long point cloud sequence. For instance, given an IMU query, we compute the similarity to each frame in a point cloud video, and retrieve the corresponding most similar or least similar moments.
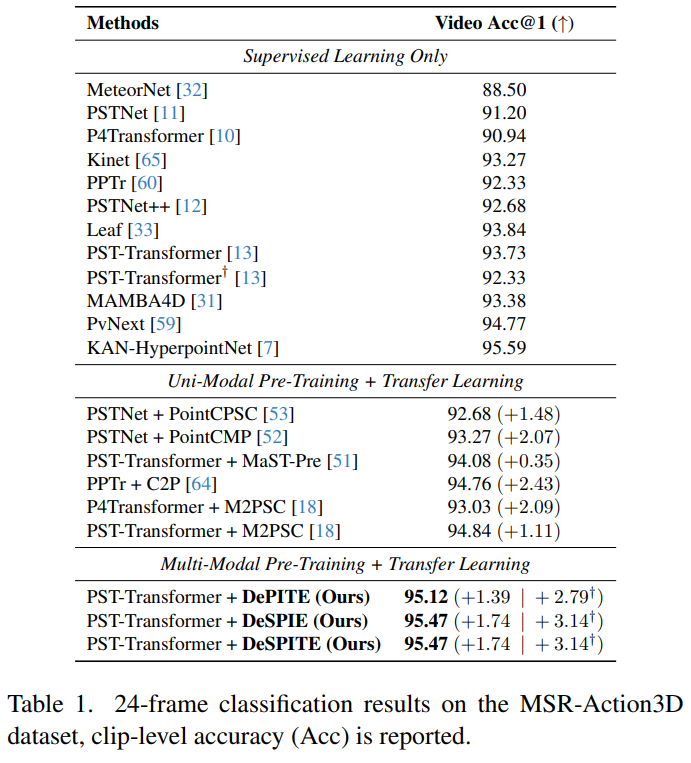
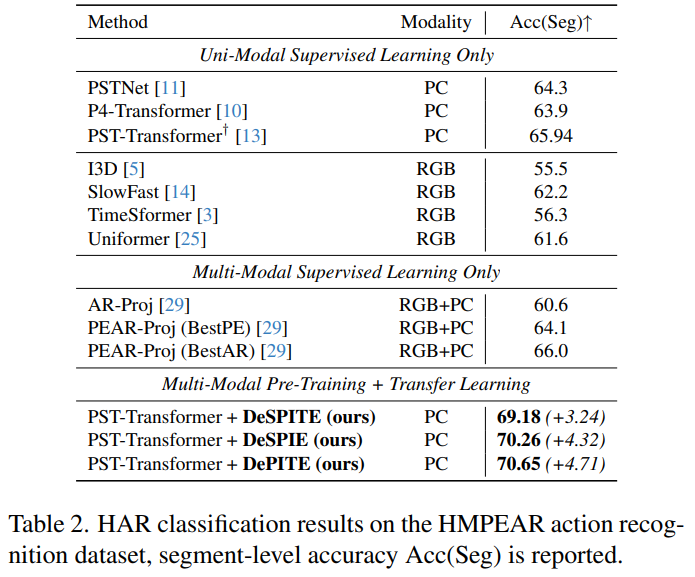
The pre-trained embeddings can be fine-tuned for, e.g., point cloud human activity recognition (HAR). We evaluate on MSR-Action3D and HMPEAR and can achieve improved performance after fine-tuning compared to training from scratch.